(iROBOCITY 2030-CM) ROBÓTICA INTELIGENTE PARA CIUDADES SOSTENIBLES. Programa de Actividades de I+D entre grupos de investigación de la Comunidad de Madrid en
Tecnologías 2024. Ref TEC-2024/TEC-62. (2025-2029)
Curso piloto de robótica en el Politécnico Colombiano Jaime Isaza Cadavid usando la plataforma web Unibotics, Proyectos de Cooperación al desarrollo, ciudadanía global y derechos humanos 2022, Universidad Rey Juan Carlos. (2023)
(UNIBOTICS-GAM) Plataforma web educativa abierta para la programación de robots en ingeniería, Proyectos de Transición Ecológica y Transición Digital 2021. Ref TED2021-132632B-I00. (2022-2024)
(MEEBAI) A Methodology for Emotion-Aware Education Based on Artificial Intelligence, Prometeo call for excellent research groups from Generalitat Valenciana. Ref:CIPROM/2021/017 (2022-2025)
(UNIBOTICS 2.0) Plataforma web educativa de programación de robots y visión artificial , Proyectos de I+D para Jóvenes Investigadores de la Universidad Rey Juan Carlos, convocatoria 2019. (2020-2021)
(RoboCity2030-DIH-CM): RoboCity2030 - Madrid Robotics Digital Innovation Hub, Programa de Actividades de I+D entre Grupos de investigación de la Comunidad de Madrid en Tecnologías 2018, Comunidad de Madrid. Ref S2018/NMT-4331 (2019-2023)
(RETOGAR), Retorno al hogar: Sistema de mejora de la autonomía de personas con daño cerebral adquirido y dependientes en su integración en la sociedad, Proyectos Excelencia y Proyectos RETOS 2016, Programa estatal de investigación, desarrollo e innovación orientada a los retos de la sociedad, Ministerio de Economía y Competitividad. Ref TIN2016-76515-R (2017-2020)
(RoboCity2030-III): Robótica aplicada a la mejora de la calidad de vida de los ciudadanos (fase III), Programa de Actividades de I+D, convocatoria Tecnologías, Comunidad de Madrid. Ref S2013/MIT-2748 (2014-2018)
(SIRMAVED): Desarrollo de un sistema integral robótico de monitorización e interacción para personas de avanzada edad y discapacitados, Ministerio de Economía y Competitividad. Ref. DPI2013-40534-R (2014-2017)
Roboterapia en Demencia, Ministerio de Sanidad, Política Social e Igualdad, Instituto de Mayores y Servicios Sociales (IMSERSO), Ref 231/2011 (2012)
Roboterapia en Demencia, Ministerio de Ciencia e Innovación. Acción estratégica de Salud. Ref:10/02567. (2010-2013)
RoboCity2030-II: Robots de servicio para la mejora de la calidad de vida de los ciudadanos en áreas metropolitanas, Comunidad Autónoma de Madrid. Ref: S2009/DPI-1559. (2010-2013).
COCOGROM: Generación de comportamientos cooperantes en Grupos de Robots móviles. Ministerio de Educación y Ciencia, Programa Nacional de Diseño y Producción Industrial. Ref: DPI2007-66556-C03-01. (2007-2010).
REDAF: Red de Agentes Físicos, Acciones Complementarias 2008 del Plan I+D+i, Ministerio de Ciencia e Innovación, Ref: TIN2008-02143-E(2009-2010)
MAVROM: Mecanismos de Atención visual en robots móviles. Comunidad de Madrid y Universidad Rey Juan Carlos. Ref: URJC-CM-2007-CET-1694. (2008)
Sistema de sensorización y monitorización de inclinación para monumentos with Orbis Terrarum Ingenieros, SL. (2007-11 to 2008-06)
Posicionamiento de cámaras móviles para anotación de secuencias de video with Visualtools, SA. (2007-10 to 2008-03)
REDAF: Red de Agentes Físicos, Acciones Complementarias 2006 del Plan I+D+i, Ministerio de Educación y Ciencia, Ref: TIN2006-27679-E (2007-2008)
Robocampeones-2007. Ministerio Ciencia y Tecnología, Programa Nacional Fomento de la cultura científica y tecnológica. Ref: CCT005-06-00275. (2006-2007).
RoboCity2030. Comunidad Autónoma de Madrid. Ref: S-0505/DPI/0176. (2006/01/01-2009/12/31).
Mecanismos de Atención visual en robots móviles. Junta de Extremadura, III Plan Regional de Investigación, Desarrollo e Innovación. Ref: 3PR05A044. (2005-2007).
ACRACE: Arquitectura para el Control de Robots Autónomos Cooperantes basada en Esquemas. Ministerio Ciencia y Tecnología, Programa Nacional de Diseño y Producción Industrial. Ref: DPI2004-07993-C03-01. (2004/12/13-2007/12/12).
Robocampeones 2005. Ministerio Ciencia y Tecnología, Plan Nacional de Difusión y Divulgación de Ciencia y Tecnología. Ref: 675963C2/CCT001-04-00121. (2004-2005)
SIS, Speed Intelligent System with Consultrans, SA. (2004-04 to 2004-09)
Robocampeones 2004 Ministerio Ciencia y Tecnología, Plan Nacional de Difusión y Divulgación de Ciencia y Tecnología. Ref: DIR2003-10282-E. (2003-2004)
Roboasist: Desarrollo de las técnicas para un sistema robótico de teleasistencia. Universidad Rey Juan Carlos, Convocatoria de proyectos de investigación 2003. Ref: GVC-2003-06. 2003-2004
RAIDER: Redes Autoconfigurables Inalámbricas Desplegando Robots Móviles. Ministerio de Ciencia y Tecnología, Programa Nacional de Tecnologías de la Información y las Comunicaciones 2001. Ref: FIT-070000-2001-118. 2001-2003.
TIER: Transmisión Inalámbrica En Robots móviles. Universidad Rey Juan Carlos, Convocatoria de proyectos de investigación 2002. Ref: PIGE-02-06. 2002-2003.
AMARA: Arquitectura jerárquica MultiAgente para la generación de comportamiento complejo en un Robot Autónomo. Ministerio Educación y Ciencia, Plan Nacional de I+D. Ref: CICYT-TAP94-0171. 1994-1997.
Simulated Aibo visual localization
[2003] María Ángeles Crespo
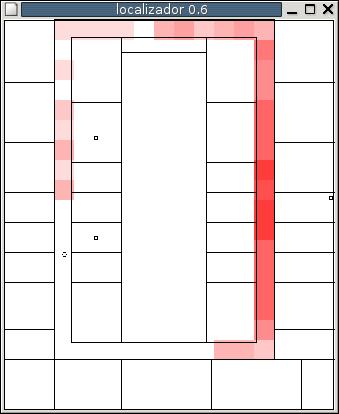
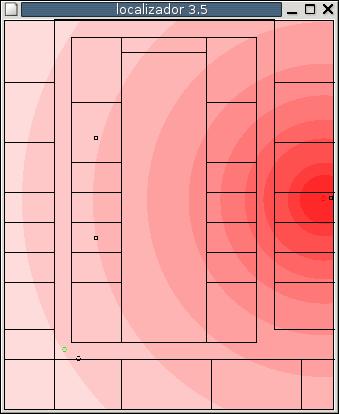
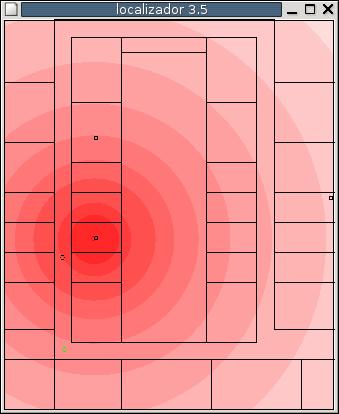
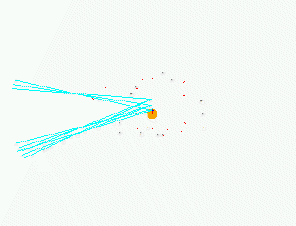
We have coded a particle filter which takes images as input, uses particles for tentative positions and updates the particle weights using a MonteCarlo method. It has been tested for a simulated RoboCup scenario with eight color beacons are placed in the border the rectangular playground (4 at the corners, 2 goals and 2 in the middle of the side lines). The evolution of the particles for a typical run is displayed in the following figure.
Second, we have explored the use of Wifi energy as a position sensor. Inside an indoor scenario, such our university floor, there are some wireless communication access points. The wifi card of the PC onboard the robot measures the received energy from such access points. We have developed a Markovian localization algorithm using such data as the main source of localization information.
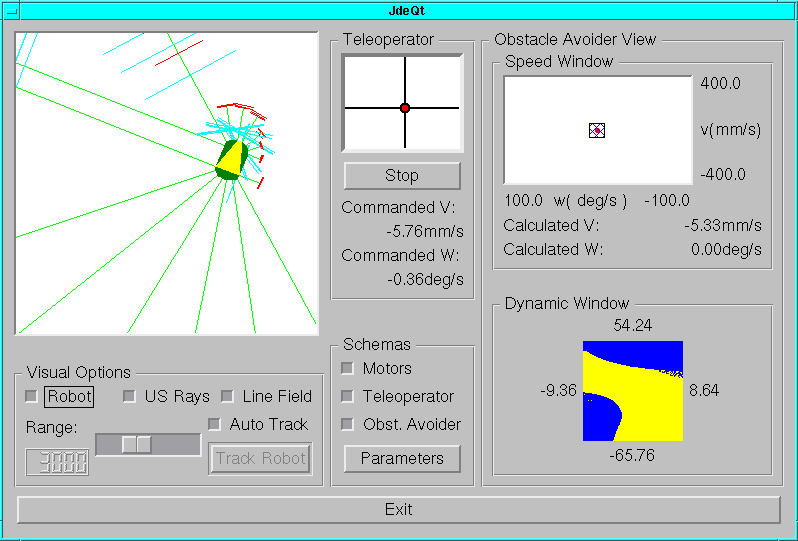
Local navigation: dynamic window
[2003] David Lobato
Regarding local navigation techniques, we have coded the Dynamic Window Approach. Speed estimation in real Pioneer was really a difficult task, so we made the experiments over the SRIsim simulator. Take a look at this video and check the speed window on the botton right.
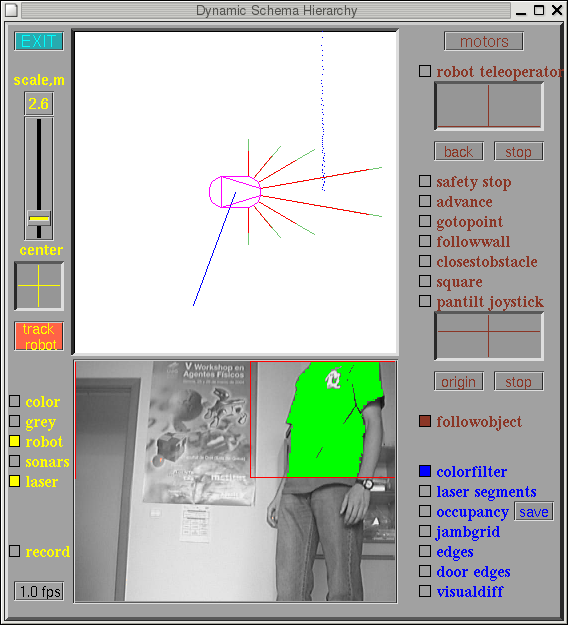
The perceptual system of the robot is a set of processes working in the background that keeps a local environment representation updated as the it walks through the world. This representation merges data coming from different sensors and obtained from different positions, and involves a kind of memory that extends the instantaneous character of sensor data. The target is to build and update a comprehensive information platform representing the robot surroundings to make good motion decisions.
Right now the environment representation is a dynamic map of the space that surrounds the robot, built on real time from sonar and odometry encoders data. The perceptual processes collect sonar measurements and buffer them in a short term memory, the red points cloud in the figure. The contents of this memory around the robot are discretized in a grid image (yellow area) and on-line clustered using a fast statistical approach, the EM algorithm, obtaining the blue fuzzy occupancy segments.
These segments and the grid fuse sensor data coming from different sonar sensors and obtained from different places. Both are suitable for a local planner which could take advantage of the information contained in them. Also they both could be used to better self-localize the robot, specially the segments. The last sonar image is also available to implement quick reactions avoiding obstacles, if needed.
Dynamic gridmaps: comparing building techniques, 2002.
The temporal properties of probabilistic, histogramic, evidence theory and fuzzy fusion rules are compared here. Two original fusion rules are also proposed, specially for sensor fusion in dynamic environments.
Visual overt attention mechanism
[2005] Marta Martínez, [2006] Olmo León
We have programmed a visual overt attention mechanism which builds and keeps updated a scene representation of all the relevant objects around a robot, especially if they are far away of each other and do not lie in the same camera image. The algorithm chooses the next fixation point for a monocular camera, which is mounted over a pantilt unit. The relevant objects are the pink ones. Our approach is based on two related dynamics: liveliness and saliency. The liveliness of each relevant object diminishes in time but increases with new observations of such object. The position of each valid object is a possible fixation point for the camera. The saliency of each fixation point increases in time but is reset after the camera visit such location. Take a look at these videos to see the algorithm in action: three objets, initial sweep and disappearing object
The algorithm has been adapted for its use with a stereo pair of cameras, and the salient objects lying in 3D space. The stereo pair is mounted on top of a pantilt unit and jumps between relevant objects in the scene, keeping updated its internal 3D representation of them. The attention system was tuned to look forward and track colored beacons and the ground limits as relevant features. Random fixation points are also included to discover new objects.
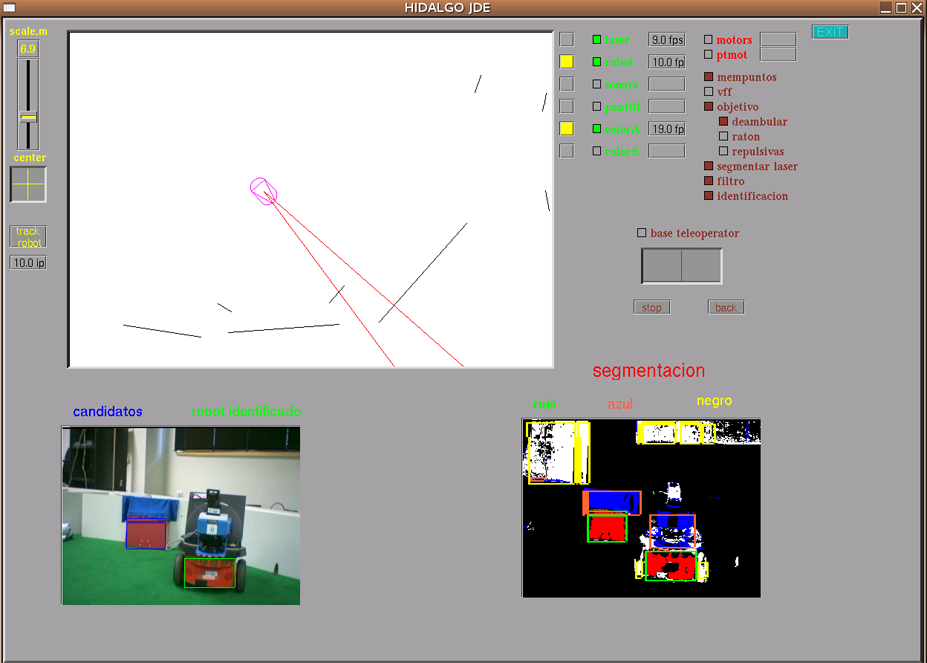
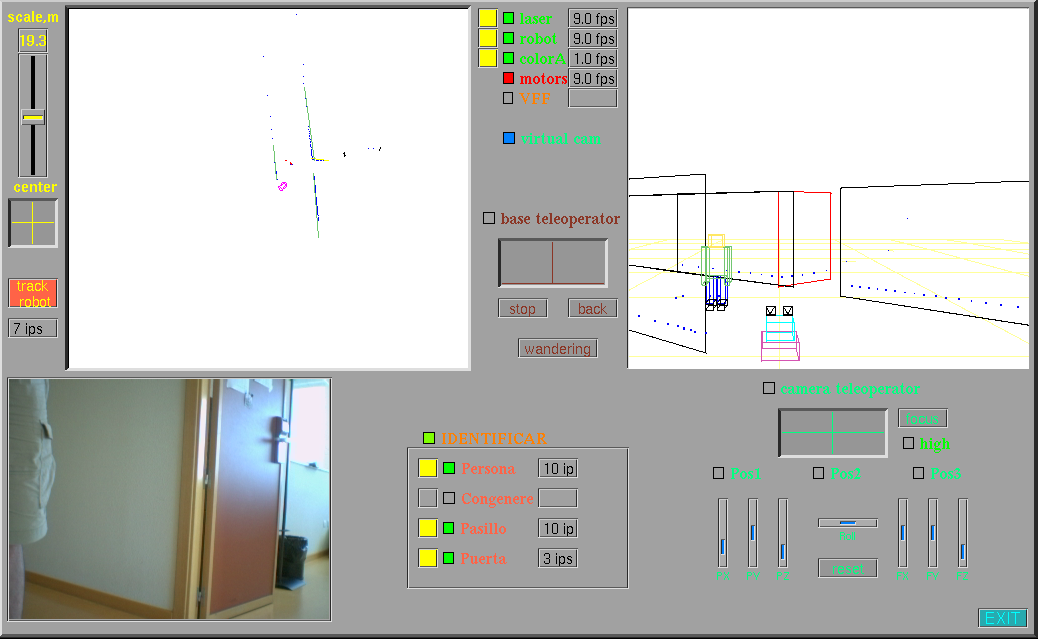
Ethological sensor fusion for perception of indoor stimuli
[2006] Víctor Hidalgo, Ricardo Palacios
A behavior of mate search, detection and pursuit was programmed for a Pioneer robot. The main issue is the mate detection, taking as sensor inputs the color images from the camera and laser readings from the rangefinder. It was carried out computing several simple substimuli like "red blob", "blue blob on top of red one", "depth appearance of the red blob", etc. (see the figure) and scoring each of them. They are combined adding such ratings, and a positive detection results when the global score is above a given threshold. This ethology based technique is fast, robust and discriminant enough as it minimizes the number of false positives and false negatives. It successfully detects any mate closer to 2.5m, regardless its relative orientation. It doesn't get confused by any fake mate, including a photo. Take a look at this video.
The same philosophy was extended to some ubiquitous stimuli in indoor environments: people, walls and doors. The combination of several simple sub-stimuli through adhoc ethologic rules builds highly selective and robust dectectors.
Wandering behavior using only monocular vision
[2005] Pedro Díaz
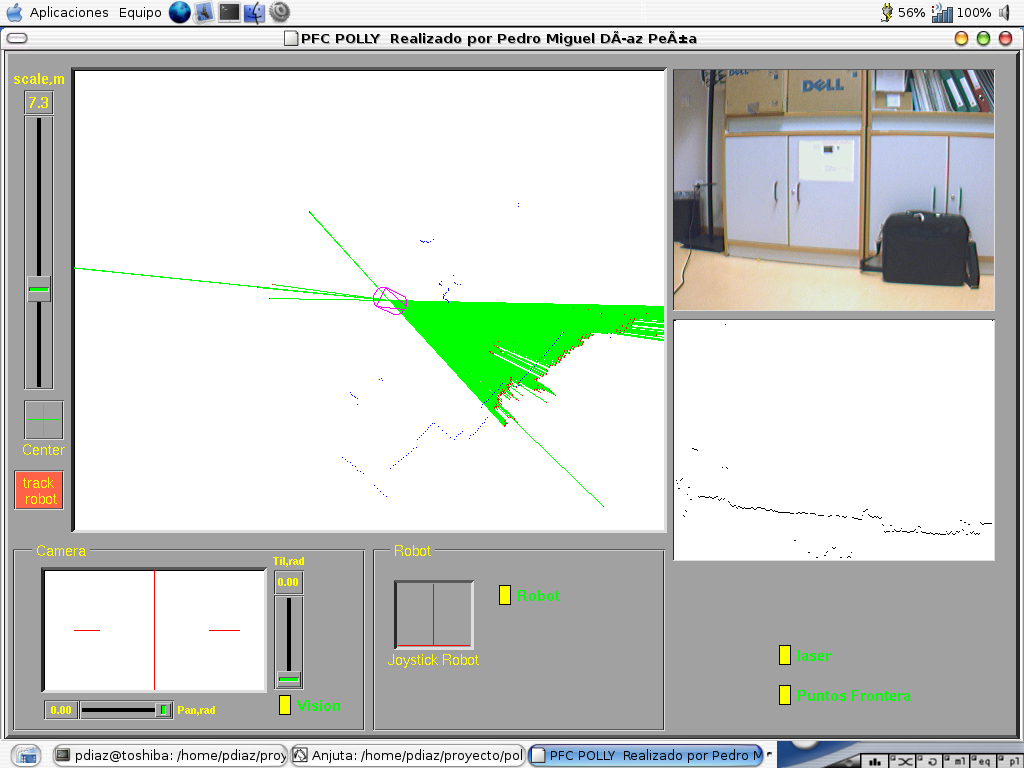
We have programmed a wandering behavior on a pioneer robot. This reincarnation of Polly robot takes as the only sensorial input the images from a monocular camera. It estimates distances to obstacles asumming that the lower part of the images matches with the floor. It continuously rotates the camera and fuse the distance estimations into a complete description of the robot surroundings, wider than the camera field of vision. Take a look at the image and compare the distance estimation (red points) with the ground truth from a laser sensor (blue points)
Person-following behavior using a monocular camera
[2004] Roberto Calvo, Ricardo Ortíz
On the Pioneer robot we've developed a person-following behavior using a monocular camera. The robot avoids obstacles in the way through and searches for the person in case of losing her in the image. We have developed two approaches. In the first, the behavior has been programmed as two JDE-schemas: a perceptive schema carries out a color filter to detect the person (wearing a colored shirt), and a motor schema implements a case-based control. It defines a rectangular safety region, just in front of the robot, to activate a Virtual Field Force (VFF) avoidance behavior. Take a look at these videos: video1 and video2.
The second approach is more complex and flexible: person-following behavior using directional vision. The robot camera is mounted on a pantilt unit which can be oriented at will. Our algorithm controls both the pantilt unit and the motor base following our behavior architecture JDE. Several JDE-schemas compose the behavior. (video1,avi)(video2,avi)
Vision-based follow-ball behaviors
[2003] Marta Martínez, [2002] Félix San Martín
In a RoboCup scenario, we have programmed two vision-based follow-ball behaviors. First, a follow ball behavior using a bird's-eye camera. The camera images were analyzed at a PC, and commands sent to the mobile EyeBot through radio link. A radio bridge was attached to PC's serial port. Two colored cards above the robot and the orange ball were located inside the image. Their pixel distance and orientation error were the inputs for the controller. Take a look at the video
Second, the follow-ball behavior with local camera. It filters the image searching for orange pixels, then clusters them in patches and selects the biggest one to follow it. The control strategy implements two Proportional feedback loops on motor speeds. Horizontal axis is used for rotation (left/right) and on vertical axis for translation (forward/backward). Take a look at the video
Follow-wall behavior with local vision
[2002] Víctor Gómez
We've developed two behaviors for the EyeBot which use its onboard camera as its only sensor. First, the follow-wall behavior. The robot filters the image searching for ground color pixels. Then it finds the frontier as the highest ground pixels in the image, and segmentate looking for straight lines. It uses a cases based control strategy depending on such segments. For instance the case in the image is the close-corner case, and the robot issues a left rotation to the motors. Take a look at the video
In conjunction with Dr. Simmons (Robot Learning Lab of Carnegie Mellon University) we've developed a visual door edge detector that works on real time and finds the door edges in the image flow. This sensor is based on edge filtering and extracts the long vertical ones from the image.
I'm currently working to locate the real door in 3D space, using those vertical edges as the visual primitive. We integrate the visual information obtained from several view points to overcome the depth ambiguity. Sonar short term memory also helps. The 3D door finder enrichs the local environment representation. The left picture shows the visual memory, with one visual ray for every door edge located in the camera images as they were collected along a teleoperated walk. On the right picture relevant intersection points are extracted and pairs of them are matched for door location, black areas mean known empty space.
Visual 3D tracking for surveillance and home automation applications
[2006] Antonio Pineda, [2007] Sara Marugán
We have programmed a surveillance application which localizes in 3D any moving object, and triggers and alarm when any object gets close enough to a protected area. The application uses 4 firewire cameras and two different techniques for 3d estimation: a particle filter and a genetic algorithm, both based on color and motion image filtering. Take a look at these videos to see the algorithms in action: 3D tracker with color and motion, and 3D tracker with only motion.
An evolutive multimodal algorithm has been developed to improve the initial system. The new application learns the color of several people walking inside a room and tracks their 3D position in real time.
Visual 3D tracking using MonteCarlo techniques
[2004-2008] Pablo Barrera
We are working on a particle filter to locate and track objects in 3D. We have coded the CONDESATION algorithm, that is a Sequential MonteCarlo tecnique, to track objects in 3D without doing any triangulation. We chose a simple gaussian pdf as dynamic state model, and define our observation model based on a color description of the object. The algorithm scales to more than two cameras and doesn't filter the entire image, just the particle projections. Take a look at some experimental results in these videos: search, tracking in small volume and tracking in big volume.
![[ROBOTICA]](logorobotica.png)